Hortonworks is the second of the three companies I own that reported on Thursday night. The first, Ichor Holdings, I wrote about yesterday. The third, Radisys, I’ll get to shortly.
I originally wrote about Hortonworks along with another company Attunity in November after doing some research on Hadoop and concluding that its adoption presented a good growth opportunity for the companies involved. At the time the stock was trading at $6, had recently been issued a sell recommendation from Goldman Sachs, and was pretty hated all around.
Nevertheless the company was growing like a weed (40% annually). It was also bleeding cash flow like a sieve. But at an enterprise value of less than 2x revenue I found it difficult to pass up the growth. Knowing Wall Street loves those growth stories, I figured a couple solid quarters would put the stock quickly back on its feet.
Fast forward a few months and that is exactly what you got. The company is still growing like a weed (revenue was up 39% in the fourth quarter, guidance was for 28% year-over-year growth in 2017), they are not bleeding cash flow quite so materially (cash flow in the fourth quarter was actually close to flat), and the stock isn’t hated quite so much.
At $11 and with a $1.40 of cash the stock is still trading at 2.4x revenue. So the valuation is actually not that different than when I bought it. One key difference is that back then the cash level was higher (roughly $130 million), the shares outstanding were lower (the company issues stock like toilet paper) and the price per share was lower, so cash was a much bigger piece of the overall valuation and that was partly what I found interesting.
The most interesting thing about the fourth quarter was that growth in their Hortonworks Data Flow platform has really taken off. I wrote about HDF in my original write-up. I’ll repeat how the company described HDF at the Pacific Crest conference last year:
Now [customers] want to have the ability to manage their data through the entire life cycle. From the point of origination, while its in motion, until it comes to rest and they want to be able to drive that entire life cycle. It fundamentally changes how they architect their data strategy going forward and the kind of applications and engagements they can have with their customers. As they’ve realized this in the last year its changed everything about their thinking about how they are driving their data architecture going forward starting with bringing the data under management for data in motion, landing it for data at rest and consolidating all the other transactional data. So it’s a very big mind shift that’s happening.
I still think HDF could be a big growth driver for the company and we are starting to see that. They said on the fourth quarter conference call that HDF grew 6x year over year in the fourth quarter.
So there is lots of reason to think growth will continue. Nevertheless, I am reluctant to add. It’s the cash flow that still gives me pause. While the fourth quarter number was good, they’ve approached break even cash flow in the past only to diverge again into big losses the following quarter. They said on the call that they expect mid-teens negative operating cash flow in the first quarter.
More optimistically, they also said that they expect break-even cash flow in the third or fourth quarter. So that would be a turning point. But then in response to a question about whether we should expect free cash flow after that, if felt like they were trying to scale back expectations:
Yes, I don’t want to talk beyond that yet, Q3, Q4 seems a long way out, but from a – if you think about free cash flow we have been running may be $2 million to $3 million a quarter on CapEx. Q4 was a little light, I think it was under $2 million, but I think once we get to the sort of breakeven number sometime between Q3 and Q4 we will reassess to how much above that we want to punch.
So I’m not sure what to think.
Hortonworks also issues a lot of stock, which while it doesn’t factor into the cash flow number, does dilute shareholder value. The shares outstanding have gone up by almost 3 million in the last couple of quarters.
On the other hand is my experience with Apigee. Another high growth company, with cash flow, that was issuing lots of shares, and the company never really sorted any of that out yet the stock tripled from the $6 price I bought it at to the almost $18 where it was bought out by Google. Hortonworks could easily follow that path.
There are certainly reasons to add. Strong growth, ramping of HDF. They announced another new product launch, enterprise data warehouse in February, and are gaining traction on their Azure and AWS offerings. They also stand to gain visually from accounting changes enacting in 2018 that will allow them to defer less revenue and spread out commission expense, in turn improving the income statement.
Nevertheless my gut, informed by the aforementioned concerns about cash generation and stock issuance, is telling me not right now.
I think if the stock pulled back on a market pullback I would be more likely to add. But it’s hard for me to double up at this price, as I have been prone to do with other ideas that start to work.
So I’ll probably sit with my 2-3% position and watch what the stock does. I prefer to take the safe route when my gut is giving me pause.
Hadoop is an open-source data management platform. It allows for easy processing and storage of really big datasets. It is an open-source initiative, meaning the software is free and written by many different companies.
Hadoop consists of a number of applications, but two are key and form the foundation of the platform; a storage system called the Hadoop Distributed File System (HDFS) and the process and an analysis framework called MapReduce.
HDFS is based on a distributed file system originally created by Google called the Google File system (GFS). The first 15 minutes of this Cloudera video provide a good explanation of the history and basic structure of that file system and its evolution into HDFS.
The analysis framework MapReduce is used to query and process data stored on the HDFS. This video describes the basic principles on which MapReduce works.
Built on top of HDFS and MapReduce are a whole bunch of other tools. These tools let you schedule jobs and manage resources (YARN), run SQL queries (HIVE), provide indexing for searching (SOLR), improve upon the processing techniques of MapReduce (IMPALA and SPARK) or even provide a simpler framework for writing Hadoop programs (PIG). There are others.
The open-source initiative on which HDFS, Mapreduce and the other tools are available is called the Apache Hadoop project. The Apache Software Foundation is the volunteer body that decides the direction of development and manage what tools will be developed and by whom. Individual companies that are member of the Apache Hadoop project propose new applications and then develop those openly for all. For example Hortonworks built YARN and put the code up on Apache and it is free for anyone, including competitors.
So what would you use Hadoop for?
Here are a few examples I came across. Imagine trying to store customer usage data from a pool of ATM’s being used across the country at a large bank. Or collecting information on driving and usage patterns of a connected car fleet. Or storing machine data from a large manufacturing operation. Or an oil and gas firm collecting real time minute by minute drilling, seismic or production data.
Any application where the data set is large, analysis of the data requires that it be stored, and where storage would be unmanageable in traditional database structures is data that would be conducive to Hadoop. Cloudera provides a number of use cases in this paper.
Hadoop is particularly useful for unstructured data sets. An unstructured data set is where the data doesn’t follow a particular table or columnar style. Social media data, mobile data, internet of things data coming straight from the device would all be typical examples of unstructured data. Conversely think of an Excel workbook, where data is laid out in a particular column by column metholology as an example of a structured data set.
Hadoop uses a methodology called schema on read that makes it particularly adept for unstructured data. Schema on read means that data that is read into HDFS does not need to have any particular structure. Instead the schema can be created at the time that the data is accessed and analyzed, at which time it can take on a form most suitable for the analytics being performed.
One feature of the HDFS storage system is that it doesn’t care what format the data is in. You can add data from an Oracle database, from an SQL database, or from an IoT application stream. HDFS doesn’t care, all the data can reside together. When you have a large database of hybrid data, usually somewhere on the cloud, its referred to as a data lake.
Hadoop Implementation
Hadoop implementation began as an on-premise extension of traditional databases. It was a response to the expanding amount of data being gathered and the unstructured nature of some of that data, which had caused requirements to surpass the capabilities of applications like Teradyne appliances.
Today, with the advent of the public cloud some customers are choosing to push data and workloads out into the cloud; to AWS or Azure for example. So far the work has been “ephemeral workloads”, which means that data is pushed out for a particular job, maybe to run analytics or reporting and then it is turned off. But as time goes on the move will likely be towards more data residing permanently on the cloud.
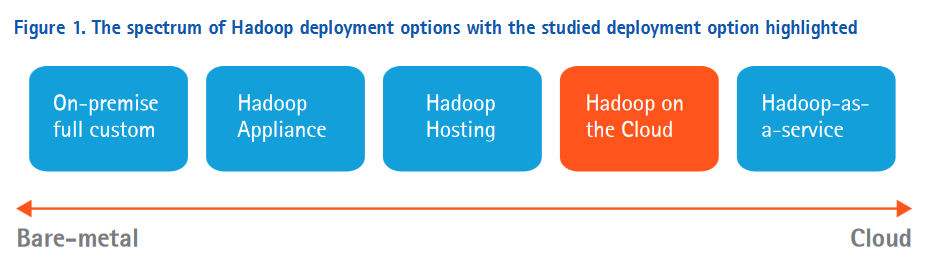
This paper by Accenture describes the deployment options and prices them out against one another. The figure below, taken from the paper, illustrates the range of implementation options.
While a company can implement Hadoop on its own, because of the complicated nature of its implementation (and from what I have read the bugginess of the code) they are more likely to contract support services from a company of experts to help with the integration.
This article lists some of the biggest players in Hadoop integration. Cloudera and MapR are both private start-ups, while Hortonworks is a public company. Each is involved with the development of the open-source applications as members of Apache.
Because Hadoop is open-source they are also limited with what product they can sell. Some, like MapR and Cloudera, have proprietary applications that work with Hadoop. Hortonworks, on the other hand, only distributes open-source software and generates revenue strictly through its implementation, support and maintenance services of the Hadoop infrastructure that they implement.
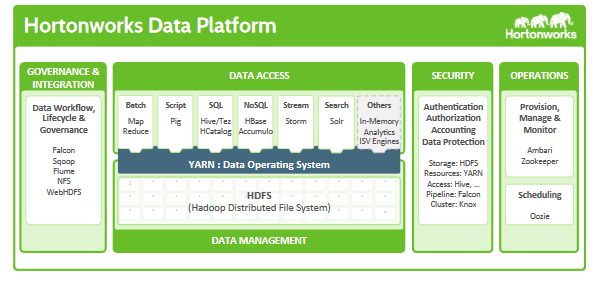
Below is the Hortonworks data platform. It consists of HDFS, a number of data access tools including MapReduce, and then supporting tools that let you manage, govern and support that data. Some of these tools (like YARN) were developed by Hortonworks, while others were developed by other Apache members (like MapR and Cloudera).
Why Invest in this Space?
There are a few trends that are converging that I am looking for ways to capitalize on.
First, the need to analyze large volumes of unstructured data, from social media, from mobile, and soon from Internet of Things devices, is going to continue to grow. Hadoop is the best technology for storing that data. In their Deutsche Bank Technology Conference presentation, Hortonworks said that there are already now 10x as many hadoop nodes as nodes on Teradata.
Second, as the cloud gains more acceptance as a trusted depository for proprietary data I think more of that data is going to find its way to Hadoop databases that exist on the cloud. So moving data to the cloud, and analyzing and managing that data on the cloud, is going to grow in importance.
Third, much of the data coming from unstructured sources is going to be best utilized if it can be analyzed soon after it is received. This sort of data analysis is referred to as “data in motion”, as opposed to “data at rest”, which is data that sits and accumulates over time. The traditional Hadoop systems are designed to store data at rest. However there are other tools, such as the Apache Spark and Kafka projects, that are tweaking Hadoop (in the case of Spark) or building a data in motion platform that can run parallel to Hadoop (in the case of Kafka) to handle data in motion.
Both types of data are going to need to work together. Historical data at rest gives context and provides learning while streaming data delivers timely insights. This very short video from Hortonworks has a good graphic that illustrates how data in motion can be ingested, analyzed and then given persistent storage in Hadoop.
I’ve been looking for ways that I can take advantage of these trends. The two companies that I have found so far are Hortonworks and Attunity.
Hortonworks
I took a small position in Hortonworks after the Goldman downgrade of the stock. I added to the position as it rose after printing a solid third quarter but have kept the position relatively small as I still have some trouble with their open-source model.
The company is growing at a 40%+ top line rate. Even after the recent move to $9 it is not expensive relative to peers growing at a similar rate. The company has an enterprise value of around $400 million and given that it generated a little under $50 million in revenue in the third quarter it is trading at less than 2x forward revenue.
The Hortonworks business model is to sell subscriptions for the integration and maintenance of their Hortonworks Data Platform (HDP) and open-source product. The revenue model is recurring and prices their services on a “per node” basis, which means that as companies scale out their Hadoop infrastructure Hortonworks takes an proportionate piece of the pie.
In addition to it Hadoop platform, Hortonworks acquired a company called Onyara in 2015 that expanded their suite of data analysis and management tools to include data in motion. From this acquisition they have developed a second platform called Hortonworks Data Flow (HDF). The HDF platform is part of another Apache project called Nifi and provides
“an infrastructure to acquire data and store it, taking into account data that has to be processed quickly to have value (low latency), discarding data after it has reached its useful limit, and d provide decision making when the data coming in is coming in faster than speed of storage.”
There is a good youtube video here (it’s a little long but the first 20 minutes is worth watching) that describes how HDF works.
HDF leverages the trend towards analyzing data as close to the point of origin as possible. The vision with HDF was expressed at the Pacific Crest conference as follows:
Now [customers] want to have the ability to manage their data through the entire life cycle. From the point of origination, while its in motion, until it comes to rest and they want to be able to drive that entire life cycle. It fundamentally changes how they architect their data strategy going forward and the kind of applications and engagements they can have with their customers. As they’ve realized this in the last year its changed everything about their thinking about how they are driving their data architecture going forward starting with bringing the data under management for data in motion, landing it for data at rest and consolidating all the other transactional data. So it’s a very big mind shift that’s happening.
Hortonworks has said that they expect HDF to make up one-third of revenue next year. That is significant growth from what is currently a small base. I think one of the most interesting aspects of Hortonworks is the growth it potentially can generate from HDF that does not seem to be adequately reflected in the stock price.
There are decent Seeking Alpha articles on Hortonworks here and here but it’s the comment sections that are particularly useful. Hortonworks also attends a lot of conferences, and their presentations at Deutsche Bank, RBC , and the previously mentioned Pacific Crest are all worth listening to.
Hortonworks reminds me a bit of Apigee. It’s a recent IPO, a fast growing company, and where some of the analyst community have lost faith in their ability to continue that growth. Therefore you have a multiple that is out of sync with the growth rate, and where a stabilization or acceleration of the growth rate (something we saw in the third quarter) should mean the stock gets re-rated to at least its prior level.
Attunity
The other way I am playing the evolution of big data lakes of unstructured data is with Attunity, which provides tools for data transfer and visibility.
Attunity has 3 main products. The main revenue driver, Attunity Replicate, facilitates the transfer of data across databases, data warehouses and Hadoop platforms. A second product, called Attunity Visibility, provides insights into your database by monitoring data usage, identify which databases/tables/columns are being used frequently and identifying who is using the data. A third product, Attunity Compose, automates many of the aspects of designing, building and managing your data warehouse.
Hadoop data lakes fit into Attunity’s product strength because they require large scale, heterogeneous, real time integration. One of the benefits of Replicate is its ability to transfer data from a wide variety of data sources. The company had this to say about the Hadoop opportunity on their first quarter call:
…the Hadoop environment creates huge opportunities for us to be more competitive and serve the markets much better. Customers are asking us basically to automate more and more the activities that are happening with Hadoop. So you really provided an end-to-end automation process and that’s one of the focuses we have.
Attunity has a bunch of case studies on their website that illustrate how Replicate and Visibility are used – most involve transferring data from a main hub (ie. A legal case file database that cannot be queried directly) or from operational databases (ie. Oil sands plant databases or retail location databases) for consolidation, to offload or to run workloads offsite.
There is also a very good SeekingAlpha article here that gives a revenue breakdown between products that is very useful. I would recommend making a copy of the article as I don’t know how long it will remain in front of the pay wall.
I’m less excited about Attunity than Hortonworks. Attunity faces a lot of competition in the extract-transfer-load market, they compete against Informatica, Oracle’s GoldenGate and SAP. Gartner recently named them a “challenger” in the magic quadrant (here is the report ). That means that they are not yet considered a leader in the field. In particular the report said:
While awareness of Attunity is starting to grow in this market, there remains a lack of recognition by buyers seeking data integration tooling as their enterprise standard.
Attunity has been growing Replicate revenues at around 25% but their legacy business has been shrinking and the Visibility product is not selling well so far. Compose remains a small portion of revenues.
So it’s a bit of a show-me story. I like the idea enough to take a starter position, but I would want to see some signs of accelerating adoption by large enterprises before adding. I would add at a higher price if I see that, because the opportunity with it, as with Hortonworks, is large.
See the end of the post for my full portfolio breakdown and the last four weeks of trades.
Thoughts and Review
I had such a good response from my post on Radisys that I decided to change things up for the blog. Rather than posting monthly letters summing up all my thoughts, I am going to deliver updates in a more traditional blog format. I will write as things come up. So this update will be more brief, and will not cover any lengthy company updates.
I had a pullback in the last month. I guess it shouldn’t be unexpected. The previous three months were almost parabolic. Having a portfolio that is weighted only to a few stocks, any kind of lull in the performance of those stocks can cause big fluctuations. Right now my portfolio is heavily dependent on the performance of Radcom and Radisys. Both stocks had corrections leading into and following their third quarter earnings.
The good news is that nothing has occurred with either to warrant a change in mind. While I expressed some concerns about Radcom in my earlier post, I felt a lot better about the stock after their Needham conference presentation. I even bought some back over the last couple days.
I sold out of a number of oil stocks. I still hold positions in Swift Energy, Journey Energy, Zargon Oil and Gas and a very tiny position in Gastar Exploration. Other than Swift Energy, none of my positions are very big. I started by selling Granite Oil after these comments on InvestorsVillage (here and here). Looks like I was wrong there. Later, as the price of oil began to break down I sold Jones Energy and Resolute Energy. Both of these are levered plays and I expect out-sized moves as oil corrects.
I added a couple of new starter positions under the theme of Big Data: Attunity and Hortonworks. The latter has begun to work out but the former has not at all. I’m doing some more work to understand if I just made a mistake on Attunity. With the new blog format I will write-up the positions and my thoughts on the Hadoop market (which led to my investments) in separate posts.
I also added a position in Nimble Storage. The company has some good technology, can compete with Pure Storage and take market share away from incumbents like NetApp. Again I’ll give more details in a later post.
Finally I mentioned in my last post that I had taken a very small position in Supernus Pharmaceuticals. I’ve held that position over the last month and watched the stock correct downwards almost every day. This is a big biotech sell-off and I don’t think the move has much to do with the company itself. Supernus is growing very fast, there appears to be plenty of opportunity for further growth, and the pipeline of new drugs seems to be quite robust. I’m seriously considering adding a big chunk to this one.
Credentials
One final thought on the topic of credentials. As I have written in the past, I manage my own family’s money. Recently I had an opportunity to expand that to a number of friends. But before going too far down that path I wanted to understand the regulatory requirements.
It turns out that in Canada at least, managing money and taking any sort of payment for it is very regulated. It requires a number of courses, which is reasonable, but also years of very specific experience under the tutorage of a dealer.
Clearly I am not going to take 3 or 4 years to work as an understudy just so I can start a small part-time business on the side for a few friends.
My frustration is that there is no distinction between someone trying to scale into a large fund, soliciting money from the general investing populace, and someone who wants to do what I was looking into; basically help out some buddies and get paid on performance to do it. These two activities do not seem equivalent in terms of public risk. But in the eyes of the regulator there is no distinction.
I’m not a conservative in most ways but this certainly gives me sympathy to the position that abhors regulation. I’m in a region that is suffering, I have a ready-made opportunity to create a small business, and the government has basically said no you can’t do that, because we know best. Because as anyone who has read this blog for the past 6 years knows, I am clearly not qualified to pick stocks.









{kind=link}