Stocksatbottom
One of the most fortunate things that happened to me as I was just beginning to invest in stocks was stumbling on an investment newsletter called Stocksatbottom.com.
This was in the early 2000s. That time wasn’t like today, what with Substack subscriptions from every Tom, Dick and Harry with an X account and a keyboard. At that time most investment subscriptions were sent to you by postal mail. An email subscription with a website was a relatively new phenomenon.
Stocksatbottom was run by a guy named Richard Stoyeck. Stoyeck talked about his “team”, but honestly I think it was just him. If you looked Stoyeck up you’d find he had been a fairly high-level guy for one of the big investment firms, I think it was Bear Stearns. But in the late-90s he got accused of insider trading and lost his job. My guess is that he was in his 50s at the time.
Anyway around 2000 Stoyeck was probably wondering what to do with himself and so he decided to start-up this little internet investment newsletter called stocksatbottom.com.
Honestly, it was one of the best educations I could have had.
Stoyeck wasn’t a great writer but he was a great writer, if you know what I mean. The stocksatbottom email alerts and round table discussions were full of grammatical errors, sentences cut off in mid stream and Stoyeck’s proficiency with this new fangled email-thingy was clearly lacking because there were often multiple fonts, multiple paragraph spacings and at time whole sections repeated within a single missive.
I also don’t think Stoyeck really cared much about selling subscriptions. The newsletter never advertised from what I can remember. At times he would go months, MONTHS, without sending out a thing.
But when Stoyeck did send something out it was a pleasure to read. Stoyeck was amazing storyteller. I have no idea if the stories he told were true but if they were he was connected to power brokers in Washington and Wall Street and he knew all kinds of inside baseball kind of info that was just so interesting to read. He’d weave these stories into a thesis about a stock. He’d start off talking about the guy he knew in the Lyndon Johnson administration that headed up the Tet offensive and was friends with Frank Sinatra and by the end of the piece he was telling why this is why you should buy Disney (btw I wonder this might be the time to buy Disney?).
It was such great stuff. When a new stocksatbottom email would show up I would actually get excited – and not “oh, a new idea to make money” excited but “I can’t wait to read this story” excited.
It really is a skill.
Anyway, there were a lot of lessons that I learned from Stocksatbottom and Stoyeck. But the one that sticks with me the most is what Stoyeck based his whole newsletter around.
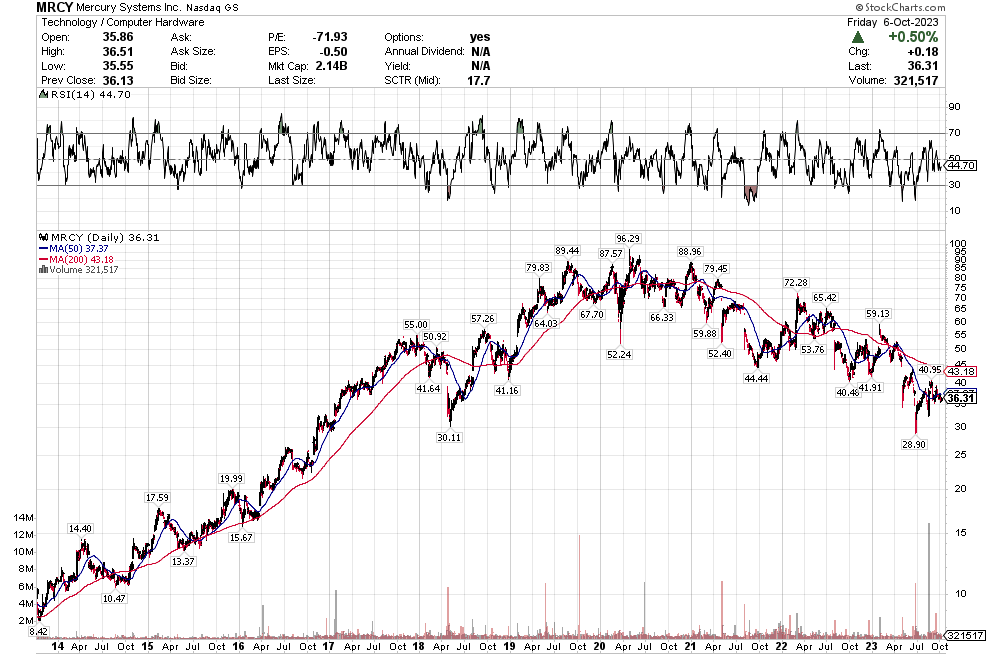
Stoyeck was like, look, you don’t have to go to small caps, you don’t have to go to micro caps to make money in stocks. Take a look at the 200 biggest stocks in the S&P. Go through their 52 week or 104 week charts. What do you see? You see ups and downs. Sometimes big ups and big downs.
Now pick one of the downs and then pick the next up. How much is the difference? It can be 30%, 50%, sometimes 80-100%.
Stoyeck was talking about stocks like GE, Bank of America, Disney, McDonalds – the big names at the time. He would say these are great companies. They aren’t going away. Sometimes they have a stumble. Disney releases John Carter. McDonalds decides to make pizza. The market goes ape-shit and says the sky is falling. You buy the stock.
It was such a simple, simple idea. Don’t over think it. Sure, check the numbers. Make sure the valuation makes sense. Sure the market has found fault in the name and there is probably good reason to have some fear. That is why the stock is down. If there wasn’t a good reason, the stock wouldn’t be down. The markets not stupid.
But as Stoyeck repeated over and over: once everyone is talking about it, it’s already in the stock. Forget about it. Ask yourself, what’s not in the stock?
Once the market forgets about what it has priced in and moves on, then it will look to the next thing. The stock starts to recover. Pretty soon the market is talking about good news. That new McCafe is taking share. I bet you that those old princess movies are ripe for another round.
That’s when you sell. Nothing goes straight up. There’s always another stock being hated and you buy that one instead.
That was the essence behind Stocksatbottom.com. Every year that I subscribed Stoyeck would wash, rinse and repeat with GE, Pfizer, Bank of America, Proctor & Gamble, Office Depot, Macys, Goldman Sachs, Walmart and so on.
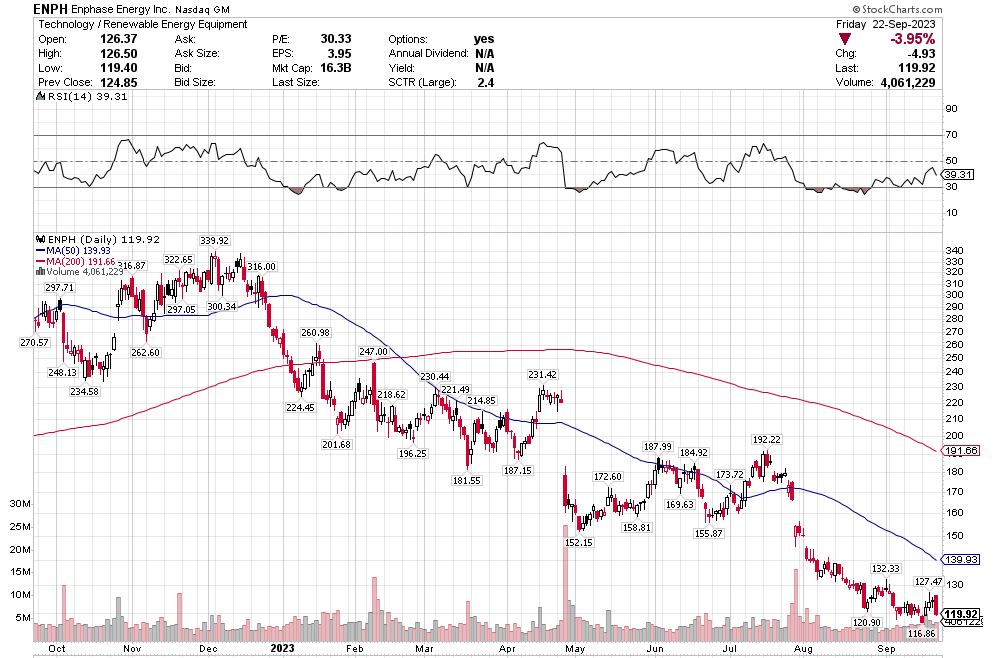
I was thinking about stocksatbottom this week because of what we went through in the last 3 months.
At the end of September I wrote this post about how much carnage there was across the market even though the indexes weren’t down that much. As is often the case, the indexes followed suit. Stocks were down big in October. It was a trying month. We were getting ready to move at the end of October, and it was probably the best timing I could have asked for because it kept me from doing anything stupid. I just sat tight with those earlier buys even as I was down a lot.
A lot of the stocks that I mentioned in that post back in September kept going down all through October. Stoyeck’s picks rarely went straight up. They usually went down first, which would make you write them off and forget them. Then he’d put out a missive 12 months later telling you he was selling that name for an 80% gain.
Some stocks I mentioned at the end of September did bottom at the beginning of October even as the market continued down. Stoyeck always said was that stocks don’t all bottom at the same time, which is why you couldn’t wait.
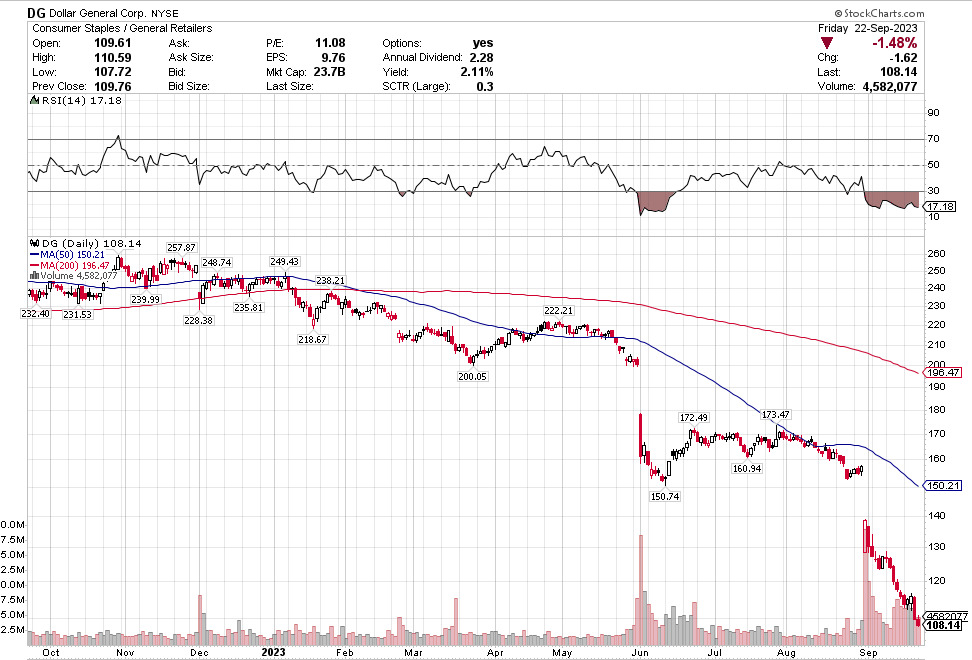
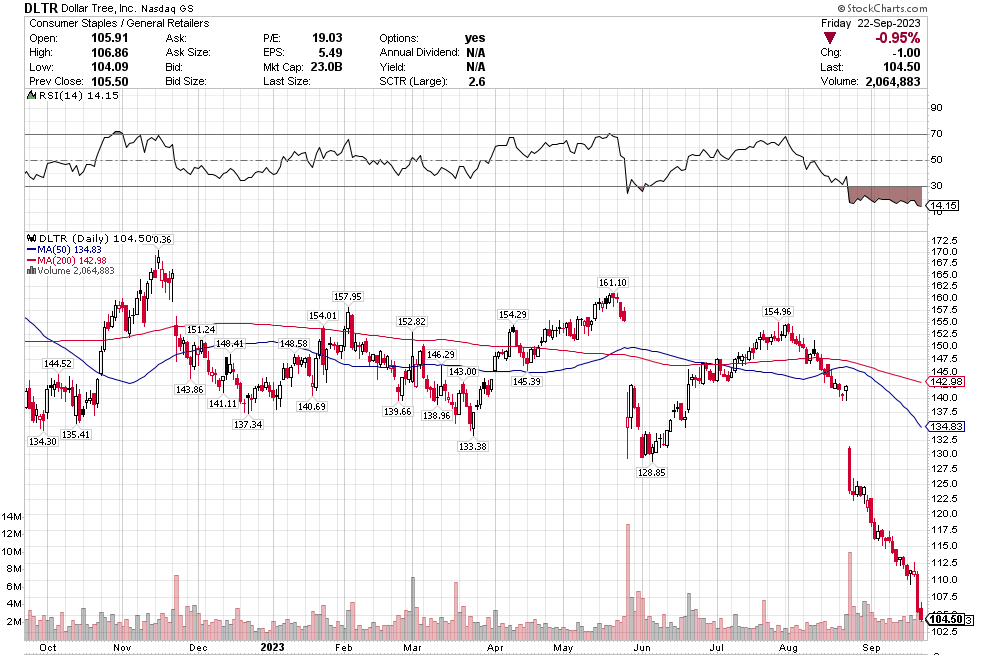
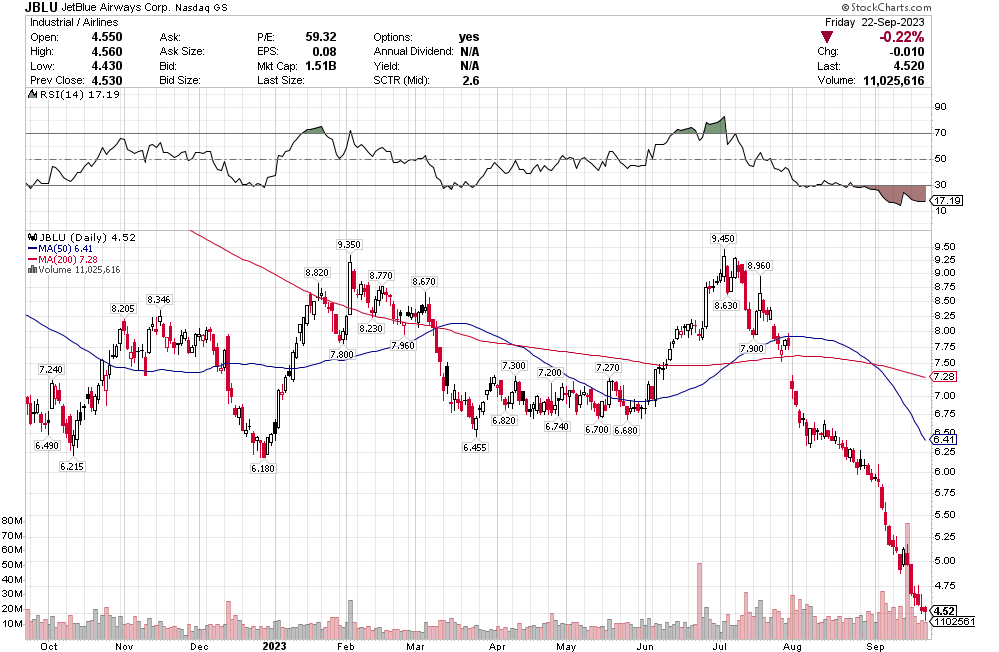
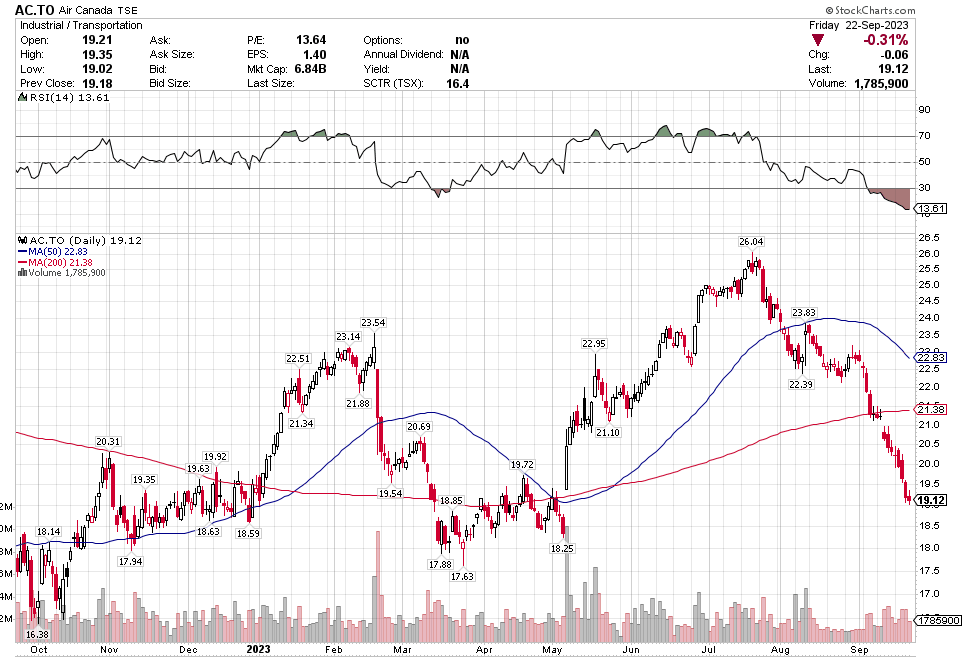
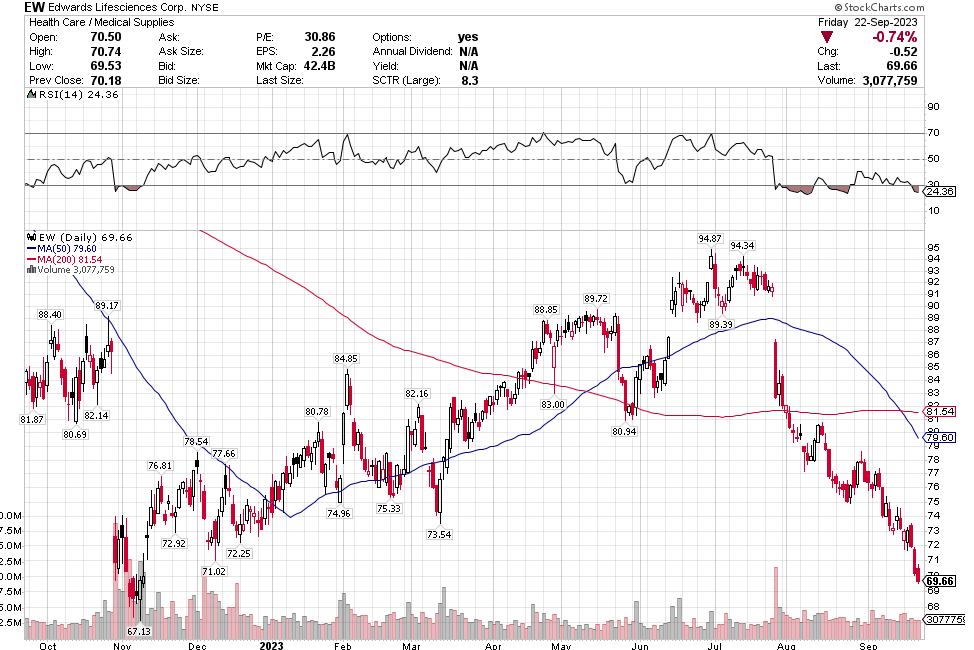
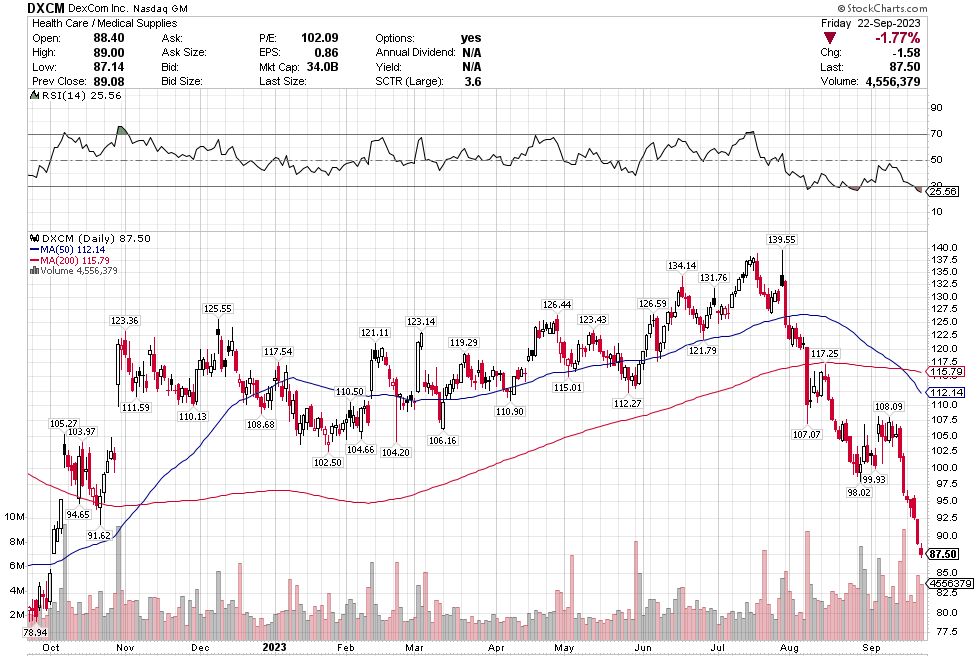
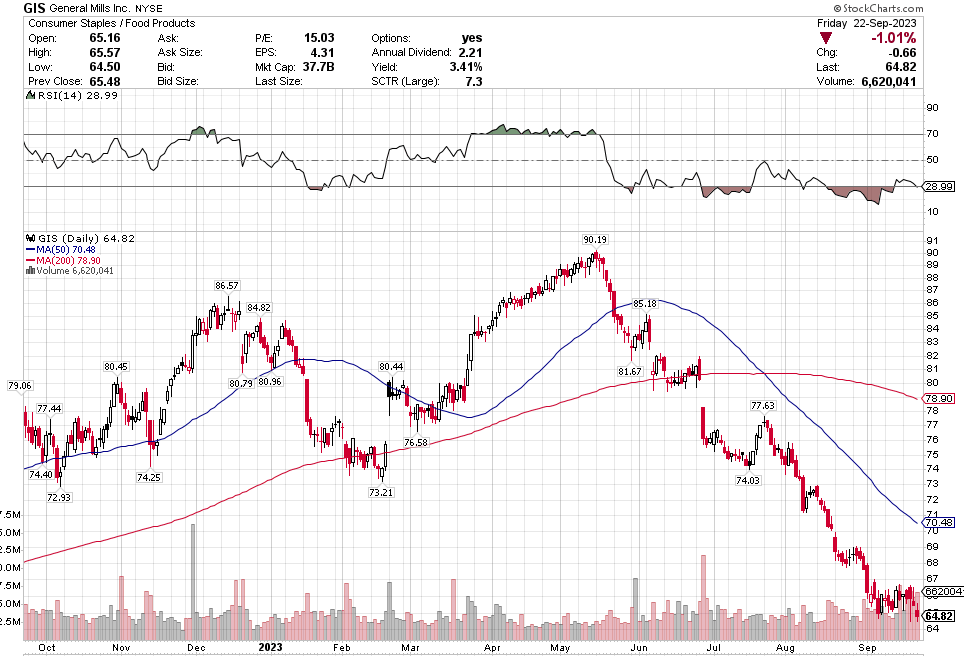
Many of the names I listed are now up. Some of them, like HD, TGT, DLTR, the medical device names, the airlines, are up a lot. There have been lots of 30%, 40% moves in medium/large caps even if you didn’t catch the bottom.
Some are not up much at all. As they say, there’s always money in the banana stand.
As Stoyeck showed and as this market swoon and rally has proven once again, there are many ways to skin a cat. You don’t have to dig into tiny microcaps, or pick SaaS growth or even find great businesses that you buy and hold forever. Stoyeck had a heck of a run by simply buying low and selling high on stocks like Bank of America and Home Depot over and over again, and telling a good story every time. Nice work if you can get it.